【Redis】大key对持久化的影响
redis大key是指占用内存过大的key
大key可能会对以下持久化方式产生影响:
- always的AOF持久化方式
- 发生写时复制时
产生的影响可能是网络阻塞、客户端请求阻塞
redis大key是指占用内存过大的key
大key可能会对以下持久化方式产生影响:
产生的影响可能是网络阻塞、客户端请求阻塞
当出现主从故障转移,但客户端并不知道或是延迟了一段时间才知道的情况下,就发生了脑裂现象
发生原因:当主服务被判定客观下线后,但客户端并没有及时被通知到并与新的主服务器建立连接。这就造成了客户端还是将要写入的数据发送给旧主服务器。然而当该旧主服务器重新上线后,它不再是主服务器,而是成为了从服务器,需要全量复制新的主服务器的数据,而这些全量复制的数据会覆盖原先已有的数据。这就造成了这一段时间内客户端写入的数据丢失。
redis通过哨兵机制来实现故障转移
哨兵的监测机制:
哨兵有多个,并且会每隔一段时间通过ping命令和主服务器建立连接来判断主服务器是否出现故障。当有一个哨兵主观判定主服务器出现故障下线后,该哨兵会请求其他哨兵再进行一次判断,如果超过一定比例的哨兵都主观认定该主服务器下线,则redis客观判定该主服务器下线。
新的主服务器选拔流程:
当旧主服务器被客观判定下线后,哨兵们会选出一个leader,一般由第一个主观判定主服务器下线的哨兵当选。
leader通过以下规则从从服务器中选出新的主服务器:1. 优先级 2.从服务器复制主服务器数据的进程 3.从服务器的id号
选出新的主服务器后,哨兵就要通过slave命令将新的主服务器的ip地址和端口号告知所有从服务器,让从服务器与新的主服务器建立连接。并且还要通过发布者/订阅模式将该地址发布到哨兵的频道上,以便客户端能够重新和新的主服务器建立连接
当旧的主服务器重新上线后,哨兵也要将该主服务器的地址告知它
redis通过采取一主多从的模式形成一个集群,以增强系统的可靠性和安全性
主服务器:负责处理读写请求,与从服务器建立连接后就将数据以全量复制的形式同步给从服务器,后续数据的更新以基于长连接的命令完成
从服务器:负责处理读请求,分散主服务器的压力
可以有多种方式来对缓存和数据库进行同步:先修改缓存再修改数据库、先修改数据库再修改缓存、先删除缓存再修改数据库、先修改数据库再删除缓存
redis选择通过先修改数据库再删除缓存来确保redis的缓存和数据库内容是一致的
但是删除缓存如果失败的话,就会造成下一次访问到的数据是脏数据。因此就需要一些机制来确保缓存删除成功。如:消息队列、订阅binlog
含义:热点数据过期被删除后,大量用户对热点数据的访问无法直接通过内存数据库得到,进而转向访问硬盘数据库,对硬盘数据库造成极大的压力,影响性能。
解决办法:建立可靠的redis集群、设置互斥锁、不对热点数据设置过期时间
含义:内存数据库宕机或者大量数据在同一时间段内过期。用户对这些数据的访问无法通过走内存数据库得到,必须访问硬盘数据库。
解决办法:建立可靠的redis集群、设置互斥锁、设置离散的过期时间
含义:用户访问数据库中不存在的数据
给每个存入redis的数据设置一个过期删除事件,过期时间一到,就自动触发事件,删除该数据
只有当使用到数据的时候,才判断该数据是否过期,过期则删除,否则,不做处理。
redis定期从过期字典里随机抽取一定数量(可以设置)的数据进行判断,如果超过一定比例(可以设置)的数据都过期了,则再进行一次随机检验,直到过期数据所占比例未达到设定值或者检验时间超时了。
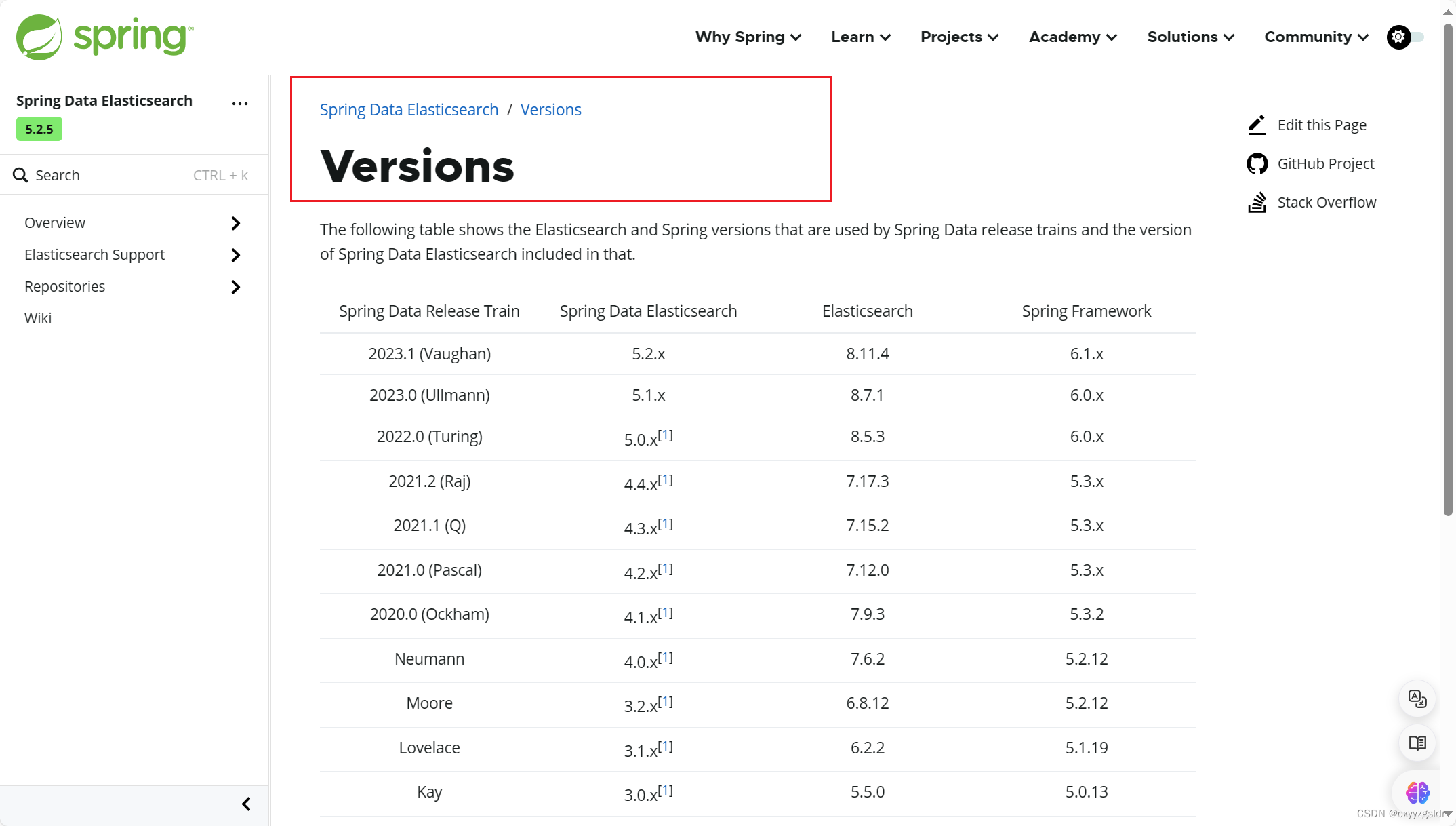
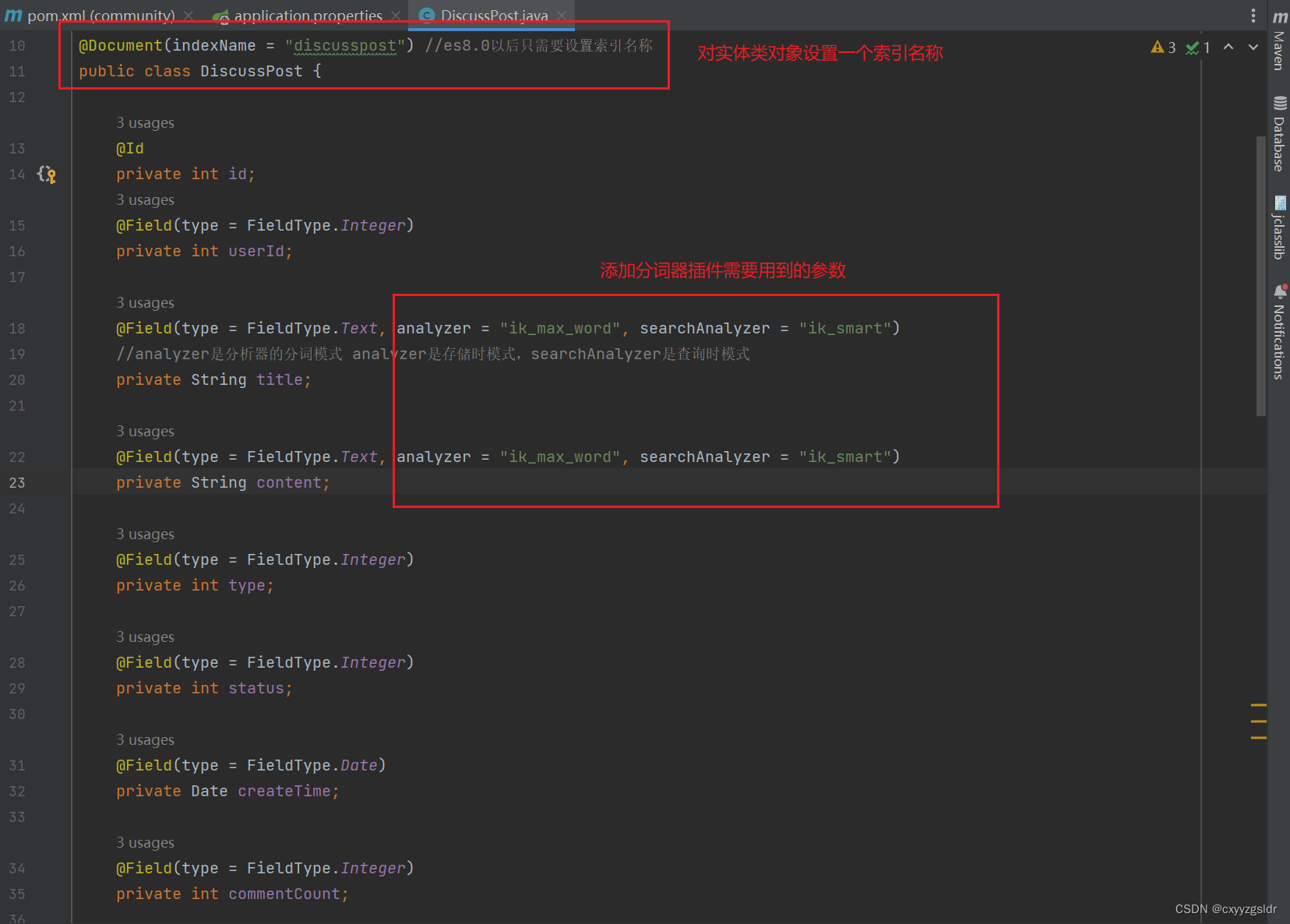
这一版的文档里没有给出springboot的版本对应,但我在一个博主的文章里看到的es8.0以前的官方文档中就有给出来,所以还需要再去寻找spring framework和springboot的对应关系???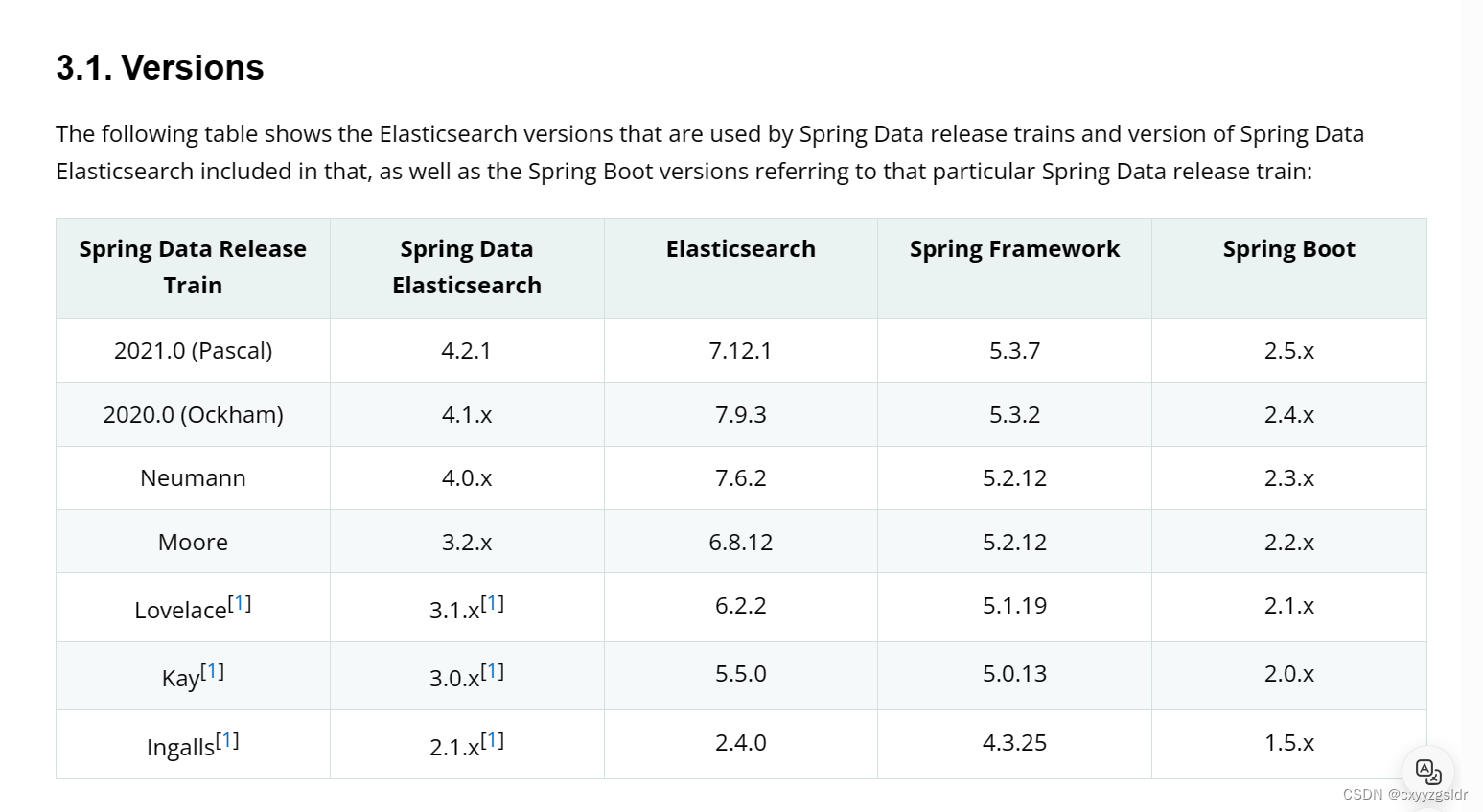
还有有个疑问,因为我选择的es依赖包是spring-boot-starter-data-elasticsearch,但官方文档里只给出了Spring Data Elasticsearch的信息,而这两者的版本对应关系我目前只能从加载的依赖包中找到,或许有其他的办法?(还请广大网友指点一下)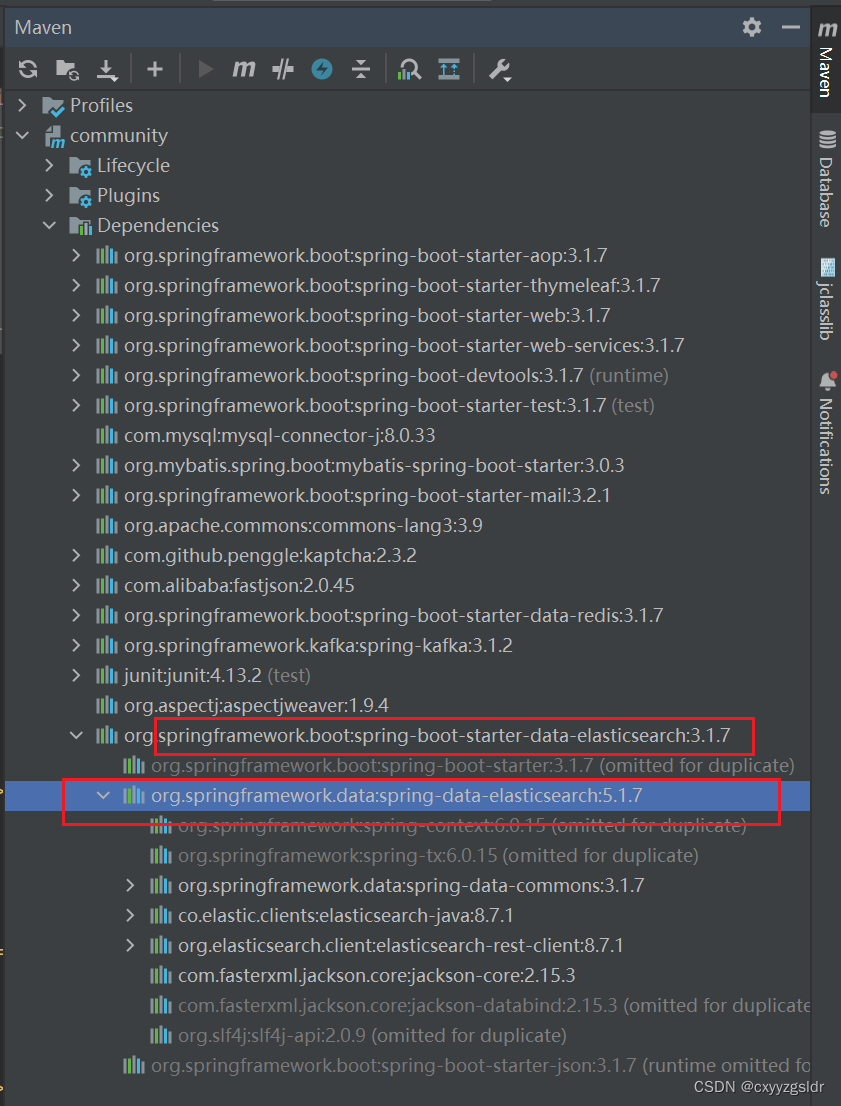
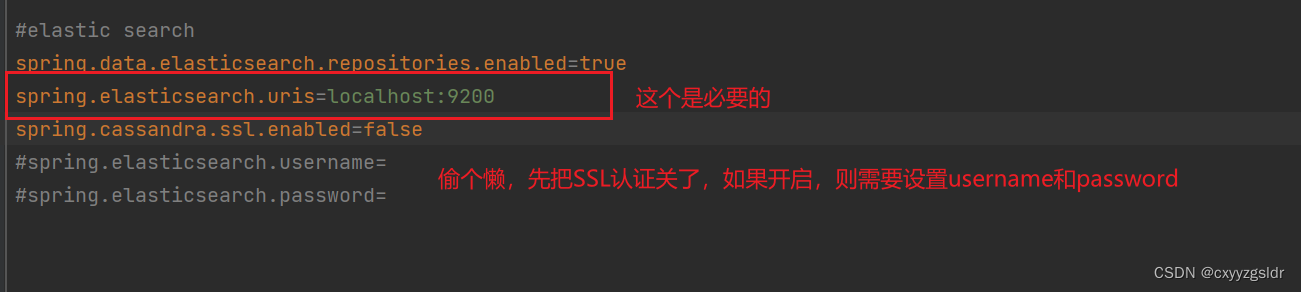
找到合适的es版本后,就可以去es官网进行下载安装了
ES安装
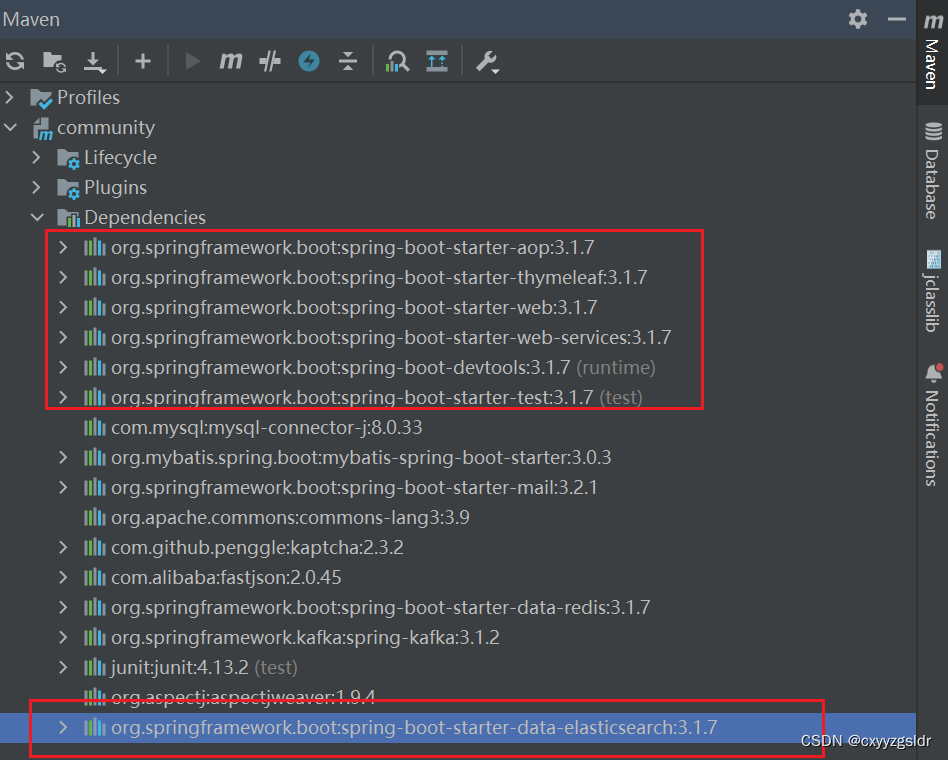
安装好es后就可以添加spring boot starter data elasticsearch的依赖包了
spring boot starter data elasticsearch的依赖包中集成了Spring Data Elasticsearch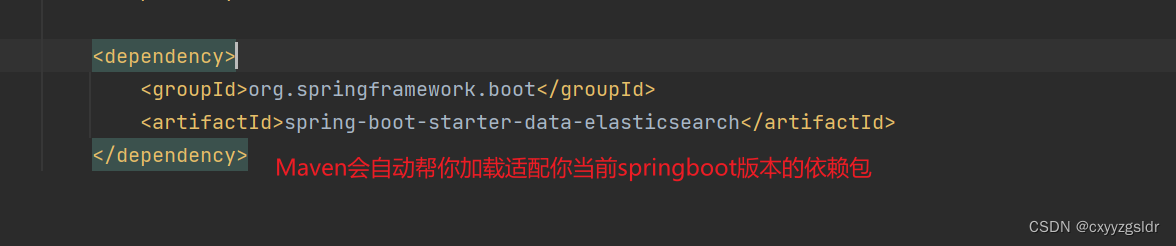
如下,我的springboot版本是3.1.7
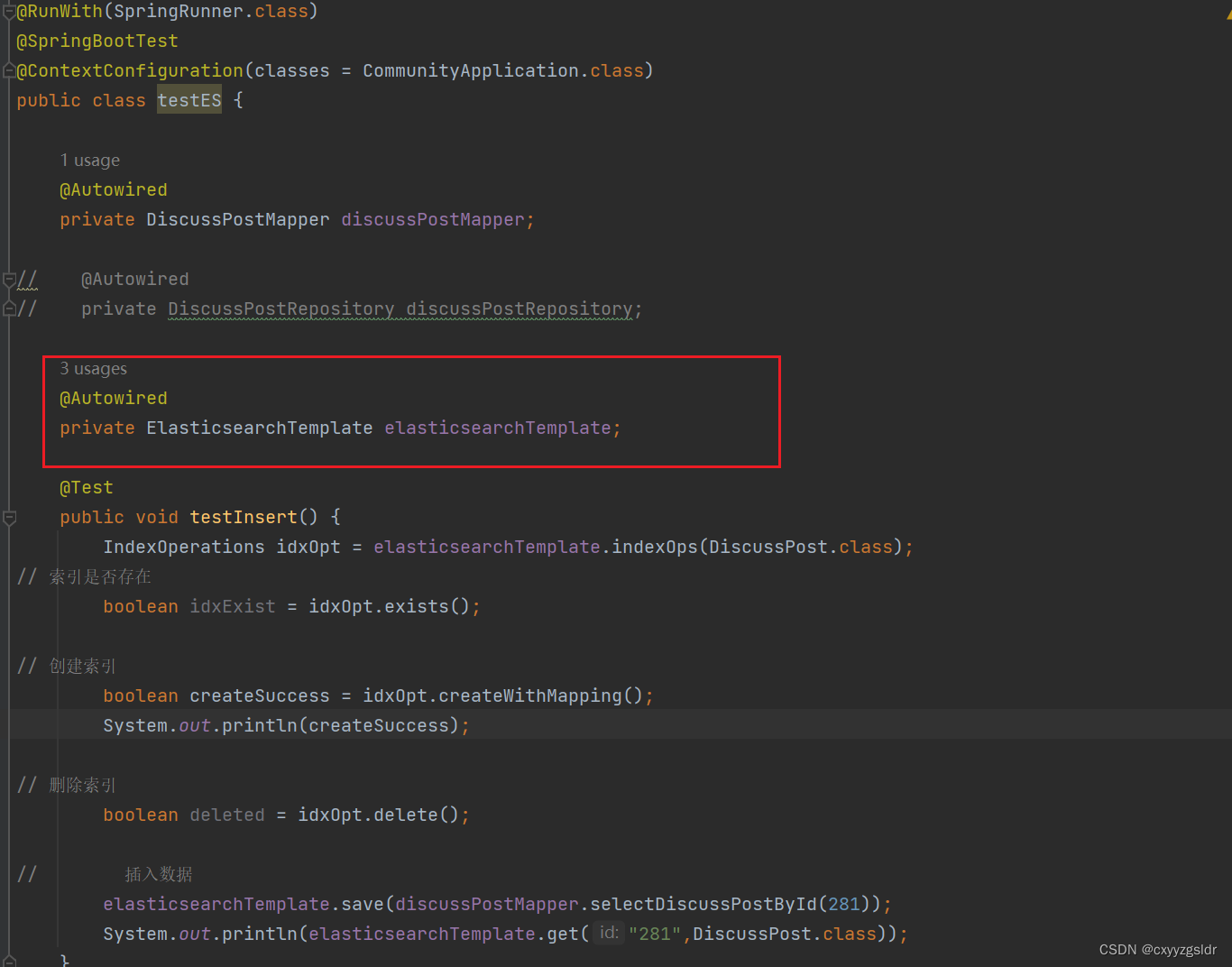
过程遇到太多坑了,尤其要注意版本适配性问题!!!
参考了很多网友的解决方案,感谢!
redis是基于内存的数据库,数据如果没有及时更新至磁盘,在系统遭遇故障后,就会造成数据丢失。因此,redis提供了两种数据持久化的方式。分别是AOF和RDB
客户端每对数据库做出一次操作,redis就会将操作以命令行的形式存入内核缓冲区的aof文件中,并根据设定的规则,按时将文件中的数据通过系统函数fsync()写回磁盘。
redis对AOF持久化方式提供了三种写回磁盘的时机。
always :每当有新的数据写入文件中,就立即将该数据写回磁盘。因为刷盘的频率最高,所以这种方式的安全性最高,但性能最差。
every second :刷盘的频率为1s,所以安全性和性能都中等。
no :不按照一定的时间间隔刷盘,而是将时机的选择交由操作系统自身来决定,具有随机性。频率最低,因此安全性最低,性能最好
RDB快照
相较于AOF是将数据库的变更以命令行的形式追加到文件中去,RDB采取的是全量复制的形式,而且是以二进制的形式进行数据的复制。也正因为每次复制都是全量复制,因此这种持久化方式的频率要比AOF低很多,但是因为是以二进制的形式存储数据,相较于AOF每次恢复的时候还需要执行命令,RDB恢复数据的时候就会快很多,直接读取即可。
redis针对RDB同样也提供了两种持久化模式。
底层由SDS(simple dynamic string)实现。主要应用场景有:计数、分布式锁、共享session信息等
底层由双向链表实现。主要应用场景有:消息队列
底层由HashMap实现。主要应用场景有:购物车等需要存储一个对象信息(多个key:value值)的场景
底层由HashMap或整数集合(intset)实现。主要应用场景有:点赞、收藏、关注等唯一性(A只能点赞一次B)场景。
底层由跳表(kiplist)实现。主要应用场景有:排行榜等需要根据一定规则来进行排序的场景
未完待续。